阿雷西博天文台:望远镜倒塌一年后?得到持续清理并开始拍摄纪录片

【菜科解读】
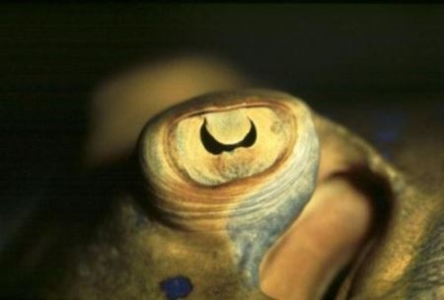
隐藏在天然天坑中的标志性射电望远镜倒塌一年后,科学家和波多黎各人仍在为失去一座有几十年历史的天文台而感到震惊。
阿雷西博天文台的射电望远镜一眼就能认出来,这要归功于它1000英尺宽(305米)的碟形天线、三个高耸入云的塔和精致的电缆网以及将科学仪器固定在碟形天线上方的平台。
但是在 2020 年末,第一根电缆出现故障,然后是第二根。
到 11 月中旬,拥有该站点的美国国家科学基金会 (NSF) 认为望远镜太不稳定而无法修复——但在该机构拆除它之前,菜叶说说,重力已经完成了这项工作。
2020 年 12 月 1 日,平台坠落,砸穿了精致的盘子。
崩溃让阿雷西博的专业科学界感到震惊——并想知道该接下来会发生什么。
一年后,这仍然是未知的。
美国国家科学基金会优先考虑清理现场,而不是对设施的未来做出任何重大决定,即使科学家们开始构思雄心勃勃的想法来继承标志性望远镜的遗产。
射电望远镜于 1963 年开始观测,其独特之处在于它是三个不同科学领域的宝贵工具:研究地球大气层、探测来自我们周围宇宙的射电光以及使用有源雷达系统研究太阳系,特别是近地小行星。
几十年来,由于出现在“GoldenEye”和“Contact”中,这台望远镜也成为波多黎各的标志,以及电影明星。
现在,望远镜开始拍摄一部新电影:“最大的梦想”,这是一部关于阿雷西博的起源、遗产和损失的纪录片。
这部电影本周在波多黎各的特别放映中首映,并计划明年开始放映。
阿雷西博天文台台长弗朗西斯科·科尔多瓦在管理阿雷西博天文台的中佛罗里达大学发布的一份声明中说:“这部电影的创作反映了波多黎各人的精神,展示了这个设施及其人民为科学界做出的巨大贡献。
”
YouTube上的预告片提供了该纪录片的一小部分。
持续清理 与此同时,在11 月 17 日发布的一份报告中,NSF 提供了自夏季以来该站点状态的首次更新。 NSF
官员在报告中写道:“紧急清理小组已经完成了大部分紧急清理和维修工作。 ”“接下来的步骤包括完成对混凝土受损区域的修复,从现场拆除工作车辆和设备以及储存打捞物品。 ” 在过去的几个月里,现场工作人员的工作包括种植绿色植物以固定土壤、测试地下水、识别和清除被液压油污染的土壤以及清除从三个支撑塔中的一个断裂的两块大混凝土。 此外,工作人员还拆除了大约 38,000
块金属板,这些金属板覆盖了碟子三分之一以上的表面,这些金属板在倒塌和清理过程中受到了损坏。 工作人员还在天文台的学习中心安装了一个临时的防飓风屋顶,并修补了游客中心屋顶和观景台的轻微损坏。 据 NSF 发言人称,对导致崩溃的原因的调查也在继续进行,尽管“迄今为止,尚未发现明显的单点故障。 ” 由于阿雷西博数十年的遗产,NSF 还必须评估如何以历史的眼光管理该站点。 尽管没有提供细节,但报告指出,NSF 和 UCF 于 6
月与波多黎各州历史保护办公室和历史保护咨询委员会会面,并计划在今年秋天再次这样做。 报告还指出,2021年,国家科学基金会成立了一个独立的打捞调查委员会,其中包括熟悉该遗址的专家,该委员会根据报告评估了“具有潜在科学、文化或历史价值的物品,这些物品将被保存下来,以便在该遗址或其他博物馆中进行潜在展示”。 该委员会的工作导致一份报告于9月提交给国家科学基金会,但该报告尚未在网上公布。 该站点科学的下一步是 11 月 17 日更新的最后一页的一角,NSF
重点介绍了今年夏天与阿雷西博科学界成员举行的研讨会系列,开始讨论阿雷西博天文台未来可能提供的机会。
CSS3转换功能transform重要属性值分析及实现
这些功能使用起来很方便。
今天我想介绍一下转换的用法:transform主要包括以下属性值:rotate(旋转度数)scale(缩放)skew(斜切扭曲)translate(对象平移)利用上述属性值,可以实现一些很酷的效果,比如正方体,下面是我做的一个效果,三个大小不等的正方体 代码如下:12345CSS3转换功能678105106107108109110111112113114115116117118119120121122123124125126127128129130131132 CSS3,转换,功能,transform,主要,属性,值,分
pytorch模型解析
近日 HuggingFace 公司开源了最新的 Transformer2.0 模型库,用户可非常方便地调用现在非常流行的 8 种语言模型进行微调和应用,且同时兼容 TensorFlow2.0 和 PyTorch 两大框架,非常方便快捷。
最近,专注于自然语言处理(NLP)的初创公司 HuggingFace 对其非常受欢迎的 Transformers 库进行了重大更新,从而为 PyTorch 和 Tensorflow 2.0 两大深度学习框架提供了前所未有的兼容性。
更新后的 Transformers 2.0 汲取了 PyTorch 的易用性和 Tensorflow 的工业级生态系统。
借助于更新后的 Transformers 库,科学家和实践者可以更方便地在开发同一语言模型的训练、评估和制作阶段选择不同的框架。
那么更新后的 Transformers 2.0 具有哪些显著的特征呢?对 NLP 研究者和实践者又会带来哪些方面的改善呢?机器之心进行了整理。
项目地址:https://GitHub.com/huggingface/transformersTransformers 2.0 新特性像 pytorch-transformers 一样使用方便;像 keras 一样功能强大和简洁;在 NLU 和 NLG 任务上实现高性能;对教育者和实践者的使用门槛低。
为所有人提供 SOTA 自然语言处理深度学习研究者;亲身实践者;AI/ML/NLP 教师和教育者。
更低的计算开销和更少的碳排放量研究者可以共享训练过的模型,而不用总是重新训练;实践者可以减少计算时间和制作成本;提供有 8 个架构和 30 多个预训练模型,一些模型支持 100 多种语言;为模型使用期限内的每个阶段选择正确的框架3 行代码训练 SOTA 模型;实现 TensorFlow 2.0 和 PyTorch 模型的深度互操作;在 TensorFlow 2.0 和 PyTorch 框架之间随意移动模型;为模型的训练、评估和制作选择正确的框架。
现已支持的模型官方提供了一个支持的模型列表,包括各种著名的预训练语言模型和变体,甚至还有官方实现的一个蒸馏后的 Bert 模型:1. BERT (https://github.com/google-research/bert) 2. GPT (https://github.com/openai/finetune-transformer-lm) 3. GPT-2 (https://blog.openai.com/better-language-models/) 4. Transformer-XL (https://github.com/kimiyoung/transformer-xl) 5. XLNet (https://github.com/zihangdai/xlnet/)6. XLM (https://github.com/facebookresearch/XLM/) 7. RoBERTa (https://github.com/pytorch/fairseq/tree/master/examples/roberta) 8. DistilBERT (https://github.com/huggingface/transformers/tree/master/examples/distillation)快速上手怎样使用 Transformers 工具包呢?官方提供了很多代码示例,以下为查看 Transformer 内部模型的代码:import torchfrom transformers import *#Transformers has a unified API#for 8 transformer architectures and 30 pretrained weights.#Model | Tokenizer | Pretrained weights shortcutMODELS = [(BertModel, BertTokenizer, ‘bert-base-uncased‘), (OpenAIGPTModel, OpenAIGPTTokenizer, ‘openai-gpt‘), (GPT2Model, GPT2Tokenizer, ‘gpt2‘), (TransfoXLModel, TransfoXLTokenizer, ‘transfo-xl-wt103‘), (XLNetModel, XLNetTokenizer, ‘xlnet-base-cased‘), (XLMModel, XLMTokenizer, ‘xlm-mlm-enfr-1024‘), (DistilBertModel, DistilBertTokenizer, ‘distilbert-base-uncased‘), (RobertaModel, RobertaTokenizer, ‘roberta-base‘)]#To use TensorFlow 2.0 versions of the models, simply prefix the class names with ‘TF‘, e.g. TFRobertaModel is the TF 2.0 counterpart of the PyTorch model RobertaModel#Let‘s encode some text in a sequence of hidden-states using each model:for model_class, tokenizer_class, pretrained_weights in MODELS: # Load pretrained model/tokenizer tokenizer = tokenizer_class.from_pretrained(pretrained_weights) model = model_class.from_pretrained(pretrained_weights) # Encode text input_ids = torch.tensor([tokenizer.encode("Here is some text to encode", add_special_tokens=True)]) # Add special tokens takes care of adding [CLS], [SEP], ... tokens in the right way for each model. with torch.no_grad(): last_hidden_states = model(input_ids)[0] # Models outputs are now tuples#Each architecture is provided with several class for fine-tuning on down-stream tasks, e.g.BERT_MODEL_CLASSES = [BertModel, BertForPreTraining, BertForMaskedLM, BertForNextSentencePrediction, BertForSequenceClassification, BertForMultipleChoice, BertForTokenClassification, BertForQuestionAnswering]#All the classes for an architecture can be initiated from pretrained weights for this architecture#Note that additional weights added for fine-tuning are only initialized#and need to be trained on the down-stream tasktokenizer = BertTokenizer.from_pretrained(‘bert-base-uncased‘)for model_class in BERT_MODEL_CLASSES: # Load pretrained model/tokenizer model = model_class.from_pretrained(‘bert-base-uncased‘)#Models can return full list of hidden-states & attentions weights at each layermodel = model_class.from_pretrained(pretrained_weights, output_hidden_states=True, output_attentions=True)input_ids = torch.tensor([tokenizer.encode("Let‘s see all hidden-states and attentions on this text")])all_hidden_states, all_attentions = model(input_ids)[-2:]#Models are compatible with Torchscriptmodel = model_class.from_pretrained(pretrained_weights, torchscript=True)traced_model = torch.jit.trace(model, (input_ids,))#Simple serialization for models and tokenizersmodel.save_pretrained(‘./directory/to/save/‘) # savemodel = model_class.from_pretrained(‘./directory/to/save/‘) # re-loadtokenizer.save_pretrained(‘./directory/to/save/‘) # savetokenizer = tokenizer_class.from_pretrained(‘./directory/to/save/‘) # re-load#SOTA examples for glue, SQUAD, text generation...Transformers 同时支持 PyTorch 和 TensorFlow2.0,用户可以将这些工具放在一起使用。
如下为使用 TensorFlow2.0 和 Transformer 的代码:#p#分页标题#e#import tensorflow as tfimport tensorflow_datasetsfrom transformers import *#Load dataset, tokenizer, model from pretrained model/vocabularytokenizer = BertTokenizer.from_pretrained(‘bert-base-cased‘)model = TFBertForSequenceClassification.from_pretrained(‘bert-base-cased‘)data = tensorflow_datasets.load(‘glue/mrpc‘)#Prepare dataset for GLUE as a tf.data.Dataset instancetrain_dataset = glue_convert_examples_to_features(data[‘train‘], tokenizer, max_length=128, task=‘mrpc‘)valid_dataset = glue_convert_examples_to_features(data[‘validation‘], tokenizer, max_length=128, task=‘mrpc‘)train_dataset = train_dataset.shuffle(100).batch(32).repeat(2)valid_dataset = valid_dataset.batch(64)#Prepare training: Compile tf.keras model with optimizer, loss and learning rate schedule optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0)loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)metric = tf.keras.metrics.SparseCategoricalAccuracy(‘accuracy‘)model.compile(optimizer=optimizer, loss=loss, metrics=[metric])#Train and evaluate using tf.keras.Model.fit()history = model.fit(train_dataset, epochs=2, steps_per_epoch=115, validation_data=valid_dataset, validation_steps=7)#Load the TensorFlow model in PyTorch for inspectionmodel.save_pretrained(‘./save/‘)pytorch_model = BertForSequenceClassification.from_pretrained(‘./save/‘, from_tf=True)#Quickly test a few predictions - MRPC is a paraphrasing task, let‘s see if our model learned the tasksentence_0 = "This research was consistent with his findings.“sentence_1 = "His findings were compatible with this research.“sentence_2 = "His findings were not compatible with this research.“inputs_1 = tokenizer.encode_plus(sentence_0, sentence_1, add_special_tokens=True, return_tensors=‘pt‘)inputs_2 = tokenizer.encode_plus(sentence_0, sentence_2, add_special_tokens=True, return_tensors=‘pt‘)pred_1 = pytorch_model(*inputs_1)[0].argmax().item()pred_2 = pytorch_model(*inputs_2)[0].argmax().item()print("sentence_1 is", "a paraphrase" if pred_1 else "not a paraphrase", "of sentence_0")print("sentence_2 is", "a paraphrase" if pred_2 else "not a paraphrase", "of sentence_0")使用 py 文件脚本进行模型微调当然,有时候你可能需要使用特定数据集对模型进行微调,Transformer2.0 项目提供了很多可以直接执行的 Python 文件。
例如:run_glue.py:在九种不同 GLUE 任务上微调 BERT、XLNet 和 XLM 的示例(序列分类);run_squad.py:在问答数据集 SQuAD 2.0 上微调 BERT、XLNet 和 XLM 的示例(token 级分类);run_generation.py:使用 GPT、GPT-2、Transformer-XL 和 XLNet 进行条件语言生成;其他可用于模型的示例代码。
GLUE 任务上进行模型微调如下为在 GLUE 任务进行微调,使模型可以用于序列分类的示例代码,使用的文件是 run_glue.py。
首先下载 GLUE 数据集,并安装额外依赖:pip install -r ./examples/requirements.txt然后可进行微调:export GLUE_DIR=http://www.studyofnet.com/path/to/glueexport TASK_NAME=MRPCpython ./examples/run_glue.py \ --model_type bert \ --model_name_or_path bert-base-uncased \ --task_name $TASK_NAME \ --do_train \ --do_eval \ --do_lower_case \ --data_dir $GLUE_DIR/$TASK_NAME \ --max_seq_length 128 \ --per_gpu_eval_batch_size=8 \ --per_gpu_train_batch_size=8 \ --learning_rate 2e-5 \ --num_train_epochs 3.0 \ --output_dir /tmp/$TASK_NAME/在命令行运行时,可以选择特定的模型和相关的训练参数。
使用 SQuAD 数据集微调模型另外,你还可以试试用 run_squad.py 文件在 SQuAD 数据集上进行微调。
代码如下:#p#分页标题#e#python -m torch.distributed.launch --nproc_per_node=8 ./examples/run_squad.py \ --model_type bert \ --model_name_or_path bert-large-uncased-whole-word-masking \ --do_train \ --do_eval \ --do_lower_case \ --train_file $SQUAD_DIR/train-v1.1.json \ --predict_file $SQUAD_DIR/dev-v1.1.json \ --learning_rate 3e-5 \ --num_train_epochs 2 \ --max_seq_length 384 \ --doc_stride 128 \ --output_dir ../models/wwm_uncased_finetuned_squad/ \ --per_gpu_eval_batch_size=3 \ --per_gpu_train_batch_size=3 \这一代码可微调 BERT 全词 Mask 模型,在 8 个 V100GPU 上微调,使模型的 F1 分数在 SQuAD 数据集上超过 93。
用模型进行文本生成还可以使用 run_generation.py 让预训练语言模型进行文本生成,代码如下:python ./examples/run_generation.py \ --model_type=gpt2 \ --length=20 \ --model_name_or_path=gpt2 \安装方法如此方便的工具怎样安装呢?用户只要保证环境在 Python3.5 以上,PyTorch 版本在 1.0.0 以上或 TensorFlow 版本为 2.0.0-rc1。
然后使用 pip 安装即可。
pip install transformers移动端部署很快就到HuggingFace 在 GitHub 上表示,他们有意将这些模型放到移动设备上,并提供了一个 repo 的代码,将 GPT-2 模型转换为 CoreML 模型放在移动端。
未来,他们会进一步推进开发工作,用户可以无缝地将大模型转换成 CoreML 模型,无需使用额外的程序脚本。
repo 地址:https://github.com/huggingface/swift-coreml-transformers