谷歌新论文把内存股价干崩了!KV cache压缩6倍,“谷歌的DeepSeek时刻”
热点
2026-03-26
菜科探索
+

简介:谷歌研究院推出TurboQuant压缩算法,把AI推理过程中最吃内存的KV cache压缩至少6倍,精度零损失。
在向量搜索领域,TurboQuant同样超越了现有最优量化方法的召回率,而且不需要针对具体数…
【菜科解读】
广告  谷歌新论文把内存股价干崩了!KV cache压缩6倍,“谷歌的DeepSeek时刻” 10:00 广告 广告 广告 了解详情 > 会员跳广告 首月9.9元 秒后跳过广告
谷歌新论文把内存股价干崩了!KV cache压缩6倍,“谷歌的DeepSeek时刻” 10:00 广告 广告 广告 了解详情 > 会员跳广告 首月9.9元 秒后跳过广告
 谷歌新论文把内存股价干崩了!KV cache压缩6倍,“谷歌的DeepSeek时刻” 10:00 广告 广告 广告 了解详情 > 会员跳广告 首月9.9元 秒后跳过广告
谷歌新论文把内存股价干崩了!KV cache压缩6倍,“谷歌的DeepSeek时刻” 10:00 广告 广告 广告 了解详情 > 会员跳广告 首月9.9元 秒后跳过广告 开通搜狐视频黄金会员,尊享更高品质体验!
1080P及以上画质仅为黄金会员专享>
开通/续费会员 抱歉,您观看的视频加载失败 请检查网络连接后重试,有话要说?请点击 我要反馈>> 正在切换清晰度... 播放 按esc可退出全屏模式 00:00 00:00 00:13 广告 只看TA 高清 倍速 剧集 字幕 下拉浏览更多 5X进行中 炫彩HDRVIP尊享HDR视觉盛宴 超清 720P 高清 540P 2.0x 1.5x 1.25x 1.0x 0.8x 50 哎呀,什么都没识别到 反馈 循环播放 跳过片头片尾 画面色彩调整 AI明星识别 视频截取 跳过片头片尾 是 | 否 色彩调整 亮度 标准 饱和度 100 对比度 100 恢复默认设置 关闭 复制全部log梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
学术会议ICLR,居然和美光和西部数据大跌扯上关系了?
两家存储芯片巨头股价大跌,没有财报暴雷,没有供应链断裂,只是谷歌展示了一篇即将在ICLR 2026正式亮相的论文。
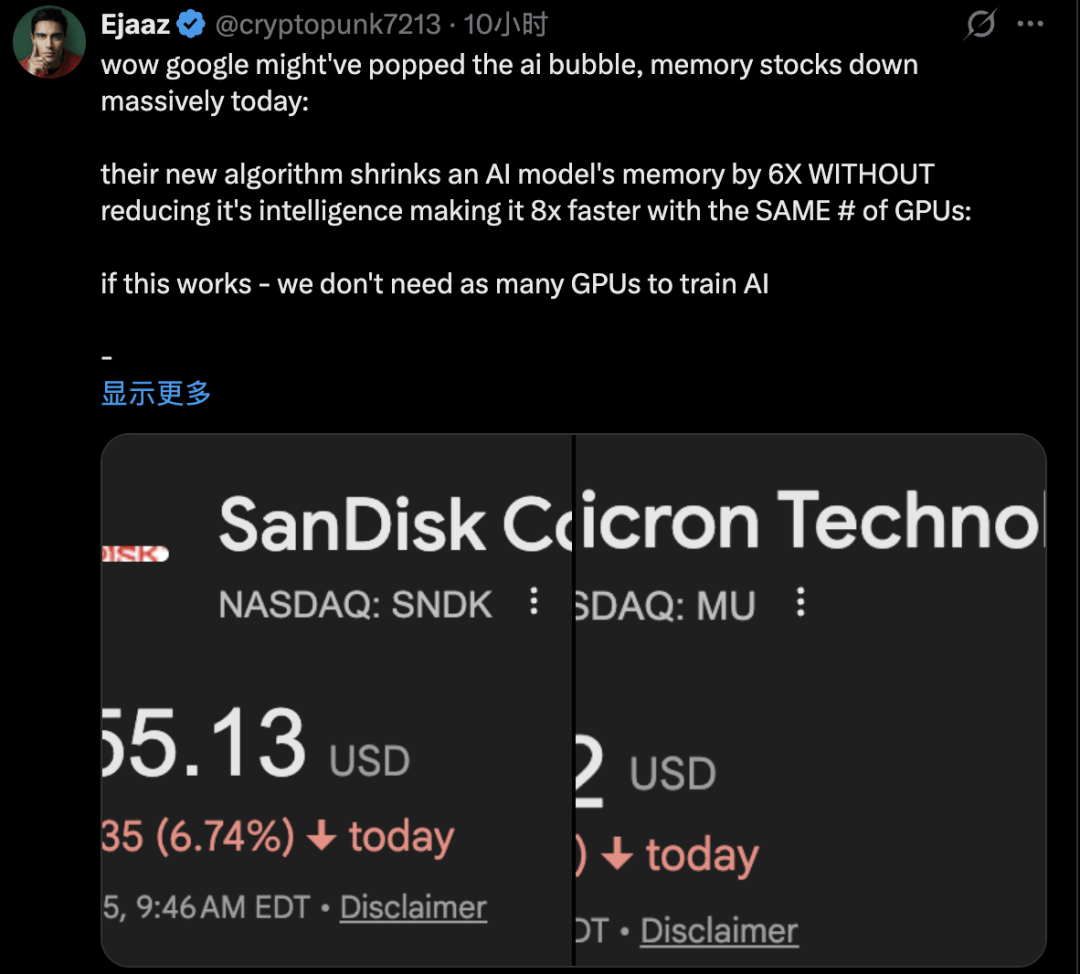
谷歌研究院推出TurboQuant压缩算法,把AI推理过程中最吃内存的KV cache压缩至少6倍,精度零损失。
市场的解读简单粗暴,长上下文AI推理以后不需要那么多内存了,利空内存。

网友纷纷表示,这不就是美剧《硅谷》里的Pied Paper?
Pied Piper是2014年开播的HBO经典美剧《硅谷》里的虚构创业公司,核心技术就是一种“近乎无损的极限压缩算法”。
2026年,类似的算法在现实世界居然成真了。
KVCache量化到3 bit
要理解TurboQuant为什么重要,先得理解它解决的是什么问题。
AI大模型推理时处理过的信息会临时存在KV Cache,方便后续快速调用,不用每次从头算起。
问题是随着上下文窗口越来越长,内存消耗急剧膨胀。
KV cache正在成为AI推理的核心瓶颈之一。
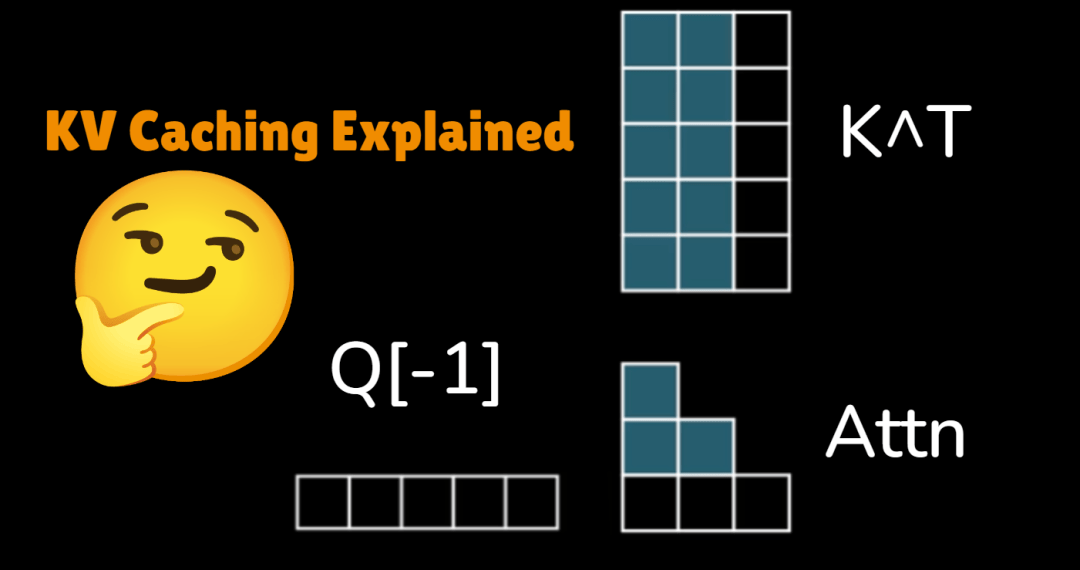
传统的解决思路是向量量化,把高精度数据压成低精度表示。
但尴尬的是,大部分量化方法本身也需要存储额外的“量化常数”,每个数字要多占1到2个bit。
TurboQuant用两个改动把这个额外开销干到了零。
PolarQuant(极坐标量化):
不用传统的X、Y、Z坐标描述数据,转而用极坐标”距离+角度”。
谷歌团队发现,转换后角度的分布非常集中且可预测,根本不需要额外存储归一化常数。
就像把“往东走3个路口,往北走4个路口”压缩成”朝37度方向走5个路口”。
信息量不变,描述更紧凑,还省掉了坐标系本身的开销。
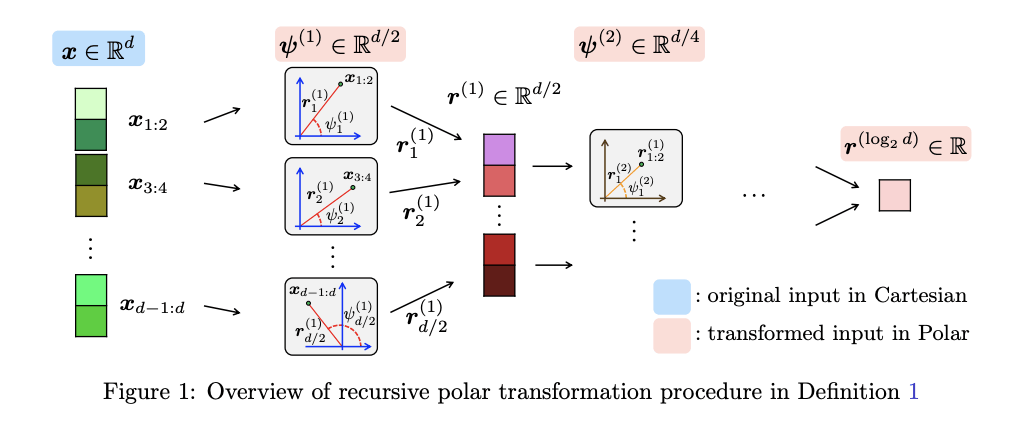
QJL(量化JL变换):
把高维数据投影后压缩成+1或-1的符号位,完全不需要额外内存。
TurboQuant用它来消除PolarQuant压缩后残留的微小误差。
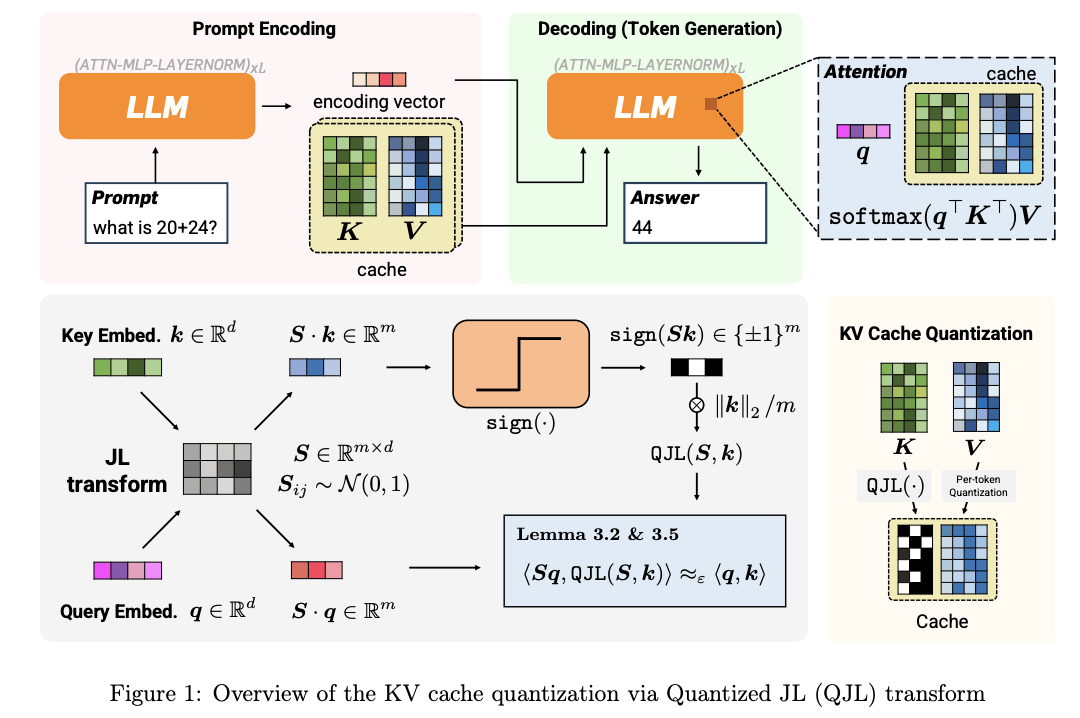
两者组合后PolarQuant先用大部分bit容量捕捉数据的主要信息,QJL再用1个bit做残差修正。
最终实现3-bit量化,无需任何训练或微调,精度零损失。
8倍加速,Benchmark全线拉满
谷歌团队在Gemma和Mistral等开源模型上,跑了主流长上下文基准测试,覆盖问答、代码生成、摘要等多种任务。
在“大海捞针”任务上,TurboQuant在所有测试中拿下完美分数,同时KV cache内存占用缩小了至少6倍。
PolarQuant单独使用,精度也几乎无损。
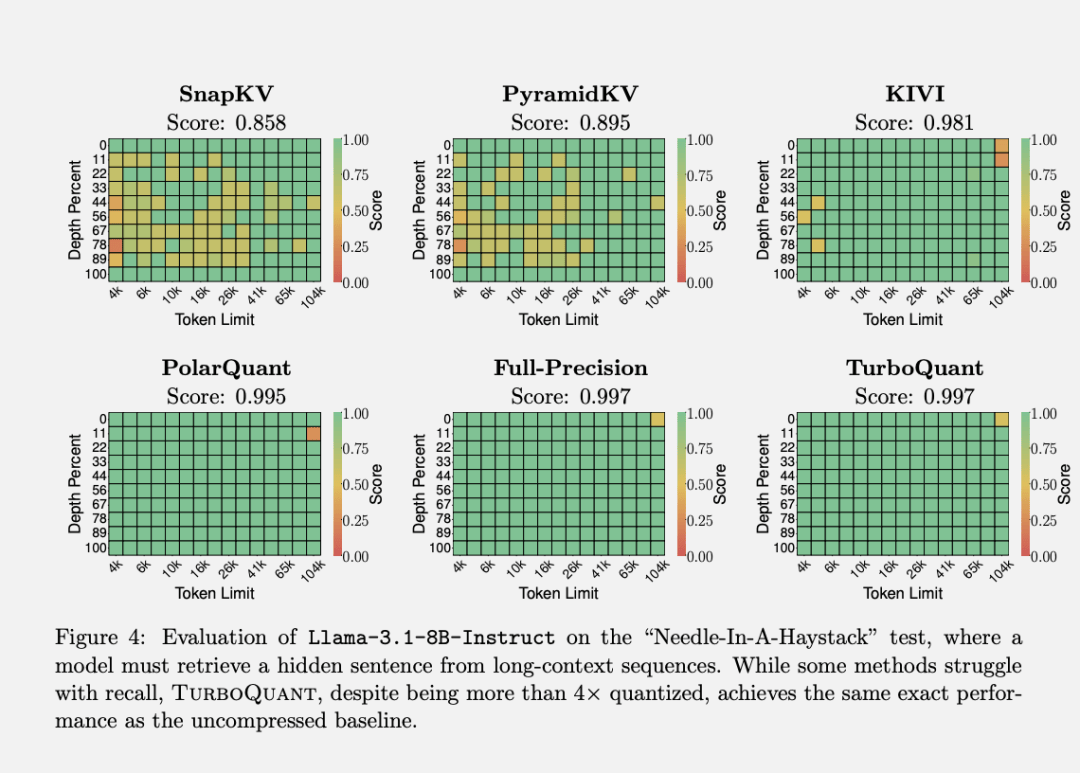
速度提升同样显著。
在英伟达H100 GPU上,4-bit TurboQuant计算注意力分数的速度,比32-bit未量化版本快了8倍。
不只是省内存,还更快了。
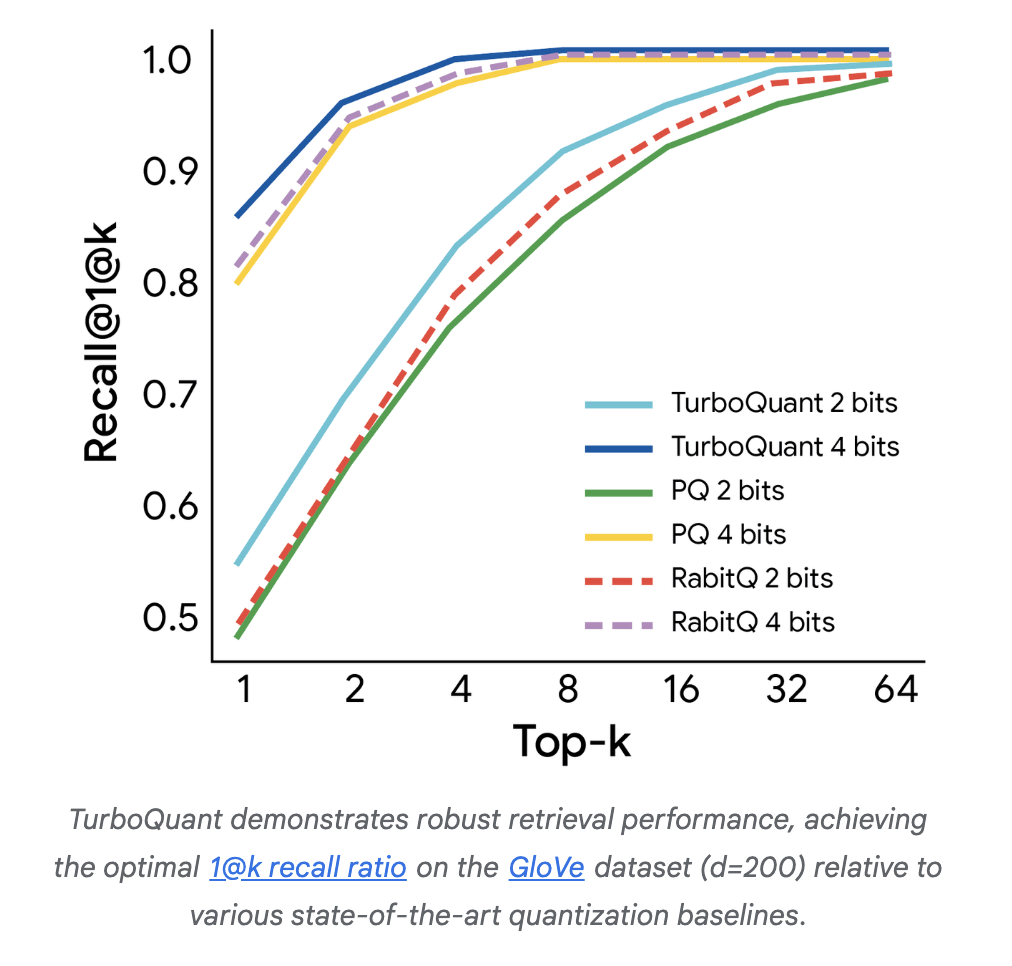
在向量搜索领域,TurboQuant同样超越了现有最优量化方法的召回率,而且不需要针对具体数据集做调优,也不依赖低效的大码本。
AI内存的DeepSeek时刻?
Cloudflare CEO评价“这是谷歌的DeepSeek时刻”。
他认为DeepSeek证明了用更少的资源也能训出顶尖模型。
TurboQuant的方向类似,用更少的内存,也能跑同样质量的推理。
谷歌表示,TurboQuant除了可以用在Gemini等大模型上,同时还能大幅提升语义搜索的效率,让谷歌级别的万亿级向量索引查询更快、成本更低。
不过TurboQuant目前还只是一个实验室成果,尚未大规模部署。
更关键的是,它只解决推理阶段的内存问题。
而AI训练环节完全不受影响。
论文地址:
https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
参考链接:
[1]https://x.com/eastdakota/status/2036827179150168182?s=20
— 欢迎AI产品从业者共建 —
英伟达力荐,小团队两个月开源一款「光速级」智能体推理引擎
机器之心编辑部 智能体时代的核心是算力。
尤其是在 Coding Agent 爆发之后,算力问题变得前所未有地尖锐。
Claude Code、Codex、Cursor 等产品正在把 AI 从「问答工具」变成「持续运行的软件协作者」,单次会话轻松突破 50K tokens,系统负载转向了更极端、更复杂的智能体负载。
最近有关算力的大新闻层出不穷。
今天的最新消息:马斯克的 SpaceX 与 Anthropic 宣布达成了重磅协议,超过 22 万块英伟达 GPU 将为 Anthropic 所用。
而 Anthropic 对与 SpaceX 合作开发未来的太空算力体系「表示有兴趣」。
在如此庞大的算力需求下,除了开源还有节流。
也是今天的最新消息:OpenAI 发布了多路径可靠连接 (MRC),可帮助大型 AI 训练集群更快、更可靠地运行,并减少 GPU 时间的浪费。
我们知道,即便只是单 GPU 吞吐率上的微小提升,一旦应用到生产级集群中,也能够在服务持续增长需求的同时,节约相当可观的算力。
来自 LightSeek Foundation 的一个小团队,在两个月时间内打造了一个全新的,号称「光速」的大模型推理引擎 TokenSpeed。
这一引擎拥有 TensorRT LLM 级别的性能,vLLM 级别的易用性。
并且拥有 NVIDIA Blackwell 上最快的 MLA 注意力内核。
一经发布,TokenSpeed 就受到了英伟达发推文力荐。
目前,该引擎已经开源。
让我们参阅其技术博客,来深入了解「光速」引擎的技术细节。
博客标题:TokenSpeed: A Speed-of-Light LLM Inference Engine for Agentic Workloads 博客链接:https://lightseek.org/blog/lightseek-tokenspeed.html Github 链接:https://github.com/lightseekorg/tokenspeed TokenSpeed 技术简介 TokenSpeed 从第一性原理出发,专门为智能体推理场景设计。
它为智能体负载提供接近「光速级」的推理能力,核心包括:基于编译器的并行建模机制、高性能调度器、安全的 KV 资源复用约束、支持异构加速器的可插拔分层 kernel 系统,以及用于低开销 CPU 侧请求入口的 SMG 集成。
建模层采用本地 SPMD(Single Program, Multiple Data,单程序多数据)设计,在性能与易用性之间取得平衡。
TokenSpeed 允许开发者在模块边界指定 I/O placement 注解。
随后,一个轻量级静态编译器会在模型构建过程中自动生成所需的 collective operation,从而无需手动实现通信逻辑。
TokenSpeed 调度器将控制平面(control plane)与执行平面(execution plane)解耦。
控制平面使用 C++ 实现,并被构建为一个有限状态机(FSM),结合类型系统,在编译期而非运行期强制执行安全资源管理,包括 KV cache 状态转移与使用。
请求生命周期、KV cache 资源以及重叠执行时序,都通过显式 FSM 状态迁移与所有权语义进行表示,因此系统正确性并非依赖约定,而是由一个可验证的控制系统来保证。
执行平面则使用 Python 实现,以保持开发效率,使研究人员与工程师能够更快进行功能迭代,并降低整体认知负载。
TokenSpeed 的 kernel 层将 kernel 从核心引擎中解耦,并将其视为一级模块化子系统。
它提供了可移植的公共 API、集中的注册与选择机制、组织良好的实现结构、面向异构加速器的可扩展插件机制、经过整理的依赖体系,以及统一的快速迭代基础设施。
与此同时,团队还针对 NVIDIA Blackwell 架构进行了大量性能优化。
例如,他们构建了当前智能体负载场景下速度最快的 MLA(Multi-head Latent Attention,多头潜在注意力)kernel 之一。
在 decode kernel 中,由于部分场景下「num_heads」较小,团队通过对「q_seqlen」与「num_heads」进行分组,以更充分利用 Tensor Core 的计算能力。
而 binary prefill kernel 则包含了经过精细调优的 softmax 实现。
目前,TokenSpeed MLA 已被 vLLM 采用。
TokenSpeed 性能预览 Coding Agents(编码智能体)带来了异常严苛的推理工作负载,上下文通常会超过 50K tokens,对话也经常跨越数十轮。
大多数公开基准测试并不能充分捕捉这种行为。
研发团队与 EvalScope 团队一起,基于 SWE-smith 轨迹对 TokenSpeed 进行评估,这些轨迹密切反映了生产环境中 Coding Agents 的流量情况。
由于生成速度对 Agent 的用户体验至关重要,因此,团队的目标是在维持单用户 TPS(每秒 token 数)下限的同时,最大化单 GPU 的 TPM(每分钟 token 数)—— 通常是 70 TPS,有时是 200 TPS 或更高。
此外,研发团队针对 TensorRT-LLM(目前 NVIDIA Blackwell 平台上的最高水平)对这一设计进行了基准测试,并在认为针对 Agentic workloads 存在更好权衡的地方,采取了与之不同的设计方案。
下图展示了在不同部署配置下(无 PD 解耦),TokenSpeed 与 TensorRT-LLM 的 Kimi K2.5 性能帕累托曲线(Pareto curves)。
每条曲线都以 TPS/User(横轴)作为延迟指标,以 TPM/GPU(纵轴)作为吞吐指标,并通过扫描并发数绘制而成。
对于 Coding Agents(高于 70 TPS/User),最佳配置是 Attention TP4 + MoE TP4。
在这一配置下,TokenSpeed 在整个帕累托前沿上均优于 TensorRT-LLM:在最低延迟场景下(batch size 1)大约快 9%,在 100 TPS/User 附近吞吐量大约高 11%。
团队表示,他们的核心优化之一是 TokenSpeed MLA。
下图对比了 TokenSpeed MLA 与 TensorRT-LLM 的 MLA,后者是目前 NVIDIA Blackwell 上的 SoTA。
可以看出来,优化后的二进制版本预填充内核(prefill kernel),使用 NVIDIA 内部旋钮来微调 softmax 实现,在 Coding Agents 的五种典型预填充工作负载(带长前缀 KV cache 的 prefill)中,都超过了 TensorRT-LLM 的 MLA。
解码内核则将查询序列轴折叠进头轴,以更好地填充 BMM1 的 M tile,从而提升 Tensor Core 利用率。
结合其他优化,在带有 speculative decoding 的典型解码工作负载中(batch size 为 4、8、16,且带长前缀 KV cache),这使得相对于 TensorRT-LLM 来说,延迟几乎降低了一半。
最后,研发团队也表示,该项目于 2026 年 3 月中旬启动开发,虽然目前展示了惊人的性能,但仍有大量底层代码(如 PD 分离、KV 存储等)正在合并和完善中,接下来将继续推进。
从上述性能表现来看,不难看出,TokenSpeed 的出现旨在通过更现代化的架构设计,打破传统推理框架在易用性与极致性能之间的平衡点,为大规模 Agent 部署提供了一个高性能、开源的底座。
而英伟达的力荐,也说明推理引擎正在成为 Agent 时代基础设施竞争的一个新焦点。
更多信息,请参阅原博客! 参考链接: https://x.com/lightseekorg/status/2052048105412141376 https://x.com/NVIDIAAI/status/2052061195381911806
特朗普曝光伊朗停火条件,伊朗60亿美元原油遭美军封锁,数据显示:收益比战前多四成
当地时间4月29日,美国总统特朗普发表约15分钟发言时表示,他拒绝了伊朗的最新停火提议。特朗普透露,伊朗的提议分三步。
第一步,伊朗先开放被自己关闭的霍尔木兹海峡;
第二步,美方撤销对伊朗港口的海上封锁;
第三步,核谈判推到这两步之后再谈。
特朗普表示:“他们想谈和。
他们不想我继续封锁。
可我不想撤。
”他补充说:“封锁比扔炸弹还狠。
” 同一天,伊朗一名匿名高级安全官员声明称,如果美方继续封锁,将面临“务实且前所未有”的反击。
美国总统特朗普 打击伊朗新计划曝光: 涉“短促猛烈”的空袭 另据报道,三名知情人士透露,美中央司令部已经备好一套针对伊朗的“短促猛烈”的空袭计划,目的是“打破谈判僵局”。
报道称,该计划的打击目标可能包括基础设施。
打完之后,美方希望“逼伊朗回到谈判桌、令其表现出更多让步”。
报道还称,特朗普在采访中没透露具体军事计划,但他在自家社交媒体平台“真实社交”上发布了一张AI合成的自己持枪图,配文“NO MORE MR. NICE GUY”(不再做好好先生)。
4月24日,中东全球事务委员会高级研究员弗雷德里克·施奈德指出,根据美国《战争权力法》,美国总统不经国会批准军事行动的窗口只有60天。
施奈德估算,特朗普批准行动的最后窗口“将于5月1日前后到期”。
回到伊朗一侧。
4月29日,伊朗高级安全官员声明称,伊朗武装力量目前在一个“战时联合指挥部”的指挥下运转。
该官员表示,伊朗有数十年规避制裁的经验、上千公里陆地边境以及战前就备好的反封锁措施;
封锁继续下去,可能“伤美国比伤伊朗更深”。
美军公开封锁数据: 伊41艘油轮被困,估值60亿美元 据报道,美国方面的封锁始于4月13日,美国海军在伊朗主要港口外设置封锁线,禁止伊朗石油船只出港。
随后,伊朗武装力量称美方此举为“非法行为”,定性为“海盗行径”。
伊朗方面的反制是把霍尔木兹海峡彻底关闭。
4月19日,伊朗第一副总统穆罕默德礼萨·阿雷夫在社交平台上发文:“不能一边卡死伊朗的石油出口,一边还指望别人在海峡里享受免费安全。
要么是所有人都享有自由的石油市场,要么是所有人都承担巨大代价。
” 4月24日,伊朗议长卡利巴夫在社交媒体声明中表示,全面停火只能在美方先解除海上封锁的前提下实现。
美军对伊朗实施海上封锁,阻止海上贸易进出其港口 4月30日,美军中央司令部(CENTCOM)司令布拉德·库珀海军上将在社交媒体上发布声明,公布了截至4月29日的封锁数据。
库珀的声明透露,41艘伊朗油轮被美军逼回伊朗港口。
船上共有6900万桶原油,估值60亿美元。
库珀表示“封锁非常有效,美军部队全力执行”。
据4月24日的公开数据计算,60亿美元约等于伊朗战前52天的石油收入。
美军封锁两周半 伊朗实际比战前还多赚了四成 来自全球石油船运数据公司Kpler显示,美军封锁后约两周半的时间里,伊朗实际比战前还多赚了四成。
伊朗战事前(今年2月初),伊朗每天石油收入约1.15亿美元。
美军的封锁开始后,因为油价稳定在每桶90美元以上,不少时候超过100美元,伊朗每天石油收入飙到约1.65亿美元。
分析称,推高伊朗收入的两个原因是:第一,中东战火推高了全球油价;
第二,伊朗趁机把战前堆在油轮上的库存以高价卖了出去。
据中东全球事务委员会高级研究员弗雷德里克·施奈德4月14日估算,封锁开始时,伊朗手里至少有1.27亿桶原油囤在海上的“漂浮油轮”里。
猜你喜欢
-
 DeepSeek-V4上线:使用华为芯片训练,性能比Gemini差3-6个月,价格优势明显 热点 2026-04-24
DeepSeek-V4上线:使用华为芯片训练,性能比Gemini差3-6个月,价格优势明显 热点 2026-04-24 -
 稀土公司副总向境外泄露7项国家秘密 国家安全部披露详情 热点 2026-04-23
稀土公司副总向境外泄露7项国家秘密 国家安全部披露详情 热点 2026-04-23 -
 恋爱技巧有哪些 热点 2026-04-22
恋爱技巧有哪些 热点 2026-04-22 -
 驻美大使谢锋:中国大蒜做梦也没想到,有朝一日会被列为“国家安全威胁” 热点 2026-04-22
驻美大使谢锋:中国大蒜做梦也没想到,有朝一日会被列为“国家安全威胁” 热点 2026-04-22 -
 警惕AI投毒陷阱:虚假信息污染数据源,误导决策需多源验证 热点 2026-04-20
警惕AI投毒陷阱:虚假信息污染数据源,误导决策需多源验证 热点 2026-04-20 -
 AI驱动数据中心爆发,光纤产销量与价格双飙升 热点 2026-04-20
AI驱动数据中心爆发,光纤产销量与价格双飙升 热点 2026-04-20 -
 京东发布JoyEgoCam超高清采集终端,赋能具身智能全链条数据基建 热点 2026-04-19
京东发布JoyEgoCam超高清采集终端,赋能具身智能全链条数据基建 热点 2026-04-19 -
 京东发布全球首个全链路具身智能数据终端JoyEgoCam 热点 2026-04-19
京东发布全球首个全链路具身智能数据终端JoyEgoCam 热点 2026-04-19 -
 中国中等收入群体:从 4 亿迈向 8 亿,超大规模市场加速成型 热点 2026-05-05
中国中等收入群体:从 4 亿迈向 8 亿,超大规模市场加速成型 热点 2026-05-05 -
 美对伊动武:理由前后打架,越说越站不住脚 热点 2026-05-05
美对伊动武:理由前后打架,越说越站不住脚 热点 2026-05-05 -
 伊朗说到做到,直接击沉一艘试图闯过霍尔木兹海峡的大型油轮 热点 2026-05-04
伊朗说到做到,直接击沉一艘试图闯过霍尔木兹海峡的大型油轮 热点 2026-05-04 -
 美国驻伊拉克埃尔比勒总领馆简介和地址 热点 2026-05-04
美国驻伊拉克埃尔比勒总领馆简介和地址 热点 2026-05-04
登录后畅享更多功能




