6个月是宝宝成长分水岭6大发育特点家长早了解别养错
怀孕
2026-05-03
菜科探索
+

简介:那6个月的 宝宝发育特点 有哪些、日常中 怎么给宝宝做好早教 、 注意些啥 呢,跟着京妈一起来学学吧。
特点一、宝宝要长牙了 信号1:口水增多。
到了6个月左右,妈妈会发现口水增多了,大多说明宝宝是要长牙了。
因为宝宝 口腔浅 、乳牙萌生时会持续刺激牙神经,进而刺激唾液腺,所以这段时期内分泌的口水会增多,那来不及吞咽的口水就会顺着嘴角
【菜科解读】
那6个月的 宝宝发育特点 有哪些、日常中 怎么给宝宝做好早教、注意些啥 呢,跟着京妈一起来学学吧。
特点一、宝宝要长牙了
信号1:口水增多。
到了6个月左右,妈妈会发现口水增多了,大多说明宝宝是要长牙了。
因为宝宝 口腔浅、乳牙萌生时会持续刺激牙神经,进而刺激唾液腺,所以这段时期内分泌的口水会增多,那来不及吞咽的口水就会顺着嘴角流出来。
【京妈建议】:
① 及时用纯棉手帕给宝宝 擦干口水;
② 可以给宝宝 戴上口水巾,这样就不用频繁的换衣服,只需更换口水巾即可;
③ 如果因为口水刺激、擦口水时对嘴巴周围皮肤的频繁摩擦而发红,可以在清洗干净后,适当涂点婴儿润肤霜;
④ 平时切记 不要用手捏宝宝的脸蛋 玩,也 不要用力亲宝宝的脸蛋,以防刺激唾液腺分泌更多的口水。
信号2:吃奶时咬奶头奶嘴,玩玩具时会咬下印子等。
这是由于乳牙萌生,宝宝牙龈会痒痛、憋涨不适,而咬东西可以缓解部分不适感。
【京妈建议】:
① 挑选质量好的 磨牙棒、牙胶 等给宝宝咬着玩,要注意勤消毒;
② 家长 多陪宝宝玩,转移他的注意力,也有助减轻牙龈不适。
特点二、宝宝要练习坐了
这个阶段,宝宝已经不满足于躺着、趴着、翻滚着,想要学习新技能了。
之前扶着宝宝坐时,宝宝可能会上身趴下去、或是东倒西歪,但这时宝宝的脊椎、腰背部肌肉力量发育 的差不多了,可以慢慢的直起腰了,因此家长也要多帮宝宝练习坐了。
【京妈建议】:
① 宝宝学坐分为三个步骤:拉坐-靠坐-独坐,一般到6个月就可以逐渐练习独坐了;
② 从靠坐到独坐,刚开始靠坐,可以先用枕头或被子围一圈,给宝宝一定的倚靠;
然后再靠着沙发坐,最后到独坐。
PS:可能有的家长会经常和周围同龄的宝宝对比,看别的宝宝会坐了,自己娃还不会坐就有点着急。
其实,每个宝宝发育不一样,会存在个体差异,要对宝宝多些耐心,平时多正确练习,学会是迟早的事儿。
特点三、宝宝可以吃新花样了
6个月前的宝宝只吃母乳或配方奶,到了6个月左右,由于母乳的营养不能完全满足宝宝的生长需求,这时就需要添加辅食了。
一来丰富宝宝口感,补充部分营养,二来锻炼宝宝的吞咽和咀嚼能力,为以后吃饭打好基础。
不过,刚开始添加辅食,建议是从强化铁的婴儿米粉开始喂。
【京妈建议】:
① 在添加时要遵 开始少而细的原则,同时观察宝宝便便没有异常、有没有过敏等,适应的好再逐渐加量,同时增加辅食种类。
② 宝宝的 第一口辅食建议是婴儿米粉,然后 逐渐添加其他泥糊状辅食,但要一样一样的添加,方便排查是否过敏。
特点四、宝宝开始认人了
半岁的宝宝喜欢对着镜子里的自己笑,并能清晰的看到妈妈的面庞,会表现出喜欢和信赖。
也是从这个阶段开始,宝宝开始认生了,碰到不熟悉的人抱他会害怕,没有安全感,因此用哭来表示不满。
【京妈建议】:
① 妈妈多陪宝宝,多和宝宝说话、玩些亲子游戏等,增强宝宝的安全感;
② 其他家庭成员 也要多和宝宝接触,慢慢建立信任;
③ 多带宝宝出去玩,接触的人多了,也有助缓解。
特点五、宝宝的运动能力变强了
这个时候的宝宝已经自己学会了一些小本领。
比如双手撑在床上,膝盖跪在那,一前一后的晃悠;趴着时小脚拍打着床面,发出咚咚的声音玩;
仰卧时会把双腿高高抬起,甚至把小脚放进嘴里,咬掉小袜子,然后玩袜子;
手部精细动作也变强了,经常会抓到东西后送往嘴巴里,而且玩具还会到手。
【京妈建议】:
① 除了帮宝宝 练习独坐 外,也可以 多让宝宝趴着,为学爬做准备,家长在宝宝前面放他喜欢的玩具,引导宝宝去抓,大人的手可以放在宝宝脚后给他助力。
② 还可以给宝宝经常玩些 适合抓握的玩具,如曼哈顿手抓球,锻炼手部精细动作、手眼协调能力、听力和注意力等。
PS:考虑到可能会被宝宝吃进嘴巴发生危险,一些小磁铁、纽扣、毛绒玩具的小零件、小电池等,最好放在宝宝抓不到的地方。
特点六、宝宝的智力发展
这个阶段的宝宝开始 用呀-啊的声音表达情绪了,有时候无意的发音像是爸爸或妈妈,但这时的发音是无意识的,宝宝并不能把这个发音和爸爸或妈妈对应起来。
宝宝的 听力也更灵敏了,能通过听声音判断是不是自己熟悉的人,并迅速转到声源处。
6个月宝宝的 眼睛 有成人的2/3大,看东西清晰了很多,视敏度也已经接近成年人水平。
【京妈建议】:
① 多陪宝宝看绘本,比如选择大图、情节简单、色彩鲜明、字少的绘本翻给宝宝看;
② 陪宝宝 玩拍手游戏、听欢快的音乐,让宝宝感受节奏感。
总之,6个月算是宝宝生长发育的一个分水岭,从趴着到坐起来,从只吃奶到逐渐添加其他食物,认知和动作的发展也有了很大进步.
但从6个月后,宝宝的免疫力会没有之前那么强了,因此也会变得爱生病。
这是这个阶段宝宝的主要特点,家长要提前了解清楚,以便更好的照顾宝宝健康生长。
你家宝宝到了6个月左右,前面这些能力都会了哪些呢?也欢迎来分享你家娃的的小本领和小趣事呀。
DeepSeek-V4上线:使用华为芯片训练,性能比Gemini差3-6个月,价格优势明显
出品|搜狐科技 作者|郑松毅、常博硕 编辑|杨锦 DeepSeek V4,来了! OpenAI GPT 5.5 前脚刚发布,DeepSeek就亮出了“真家伙”。就在刚刚,DeepSeek-V4的预览版本正式上线并同步开源。
据官方介绍,DeepSeek-V4拥有百万字超长上下文,在 Agent 能力、世界知识和推理性能上均实现国内与开源领域的领先。
模型按大小分为两个版本: 更具产业里程碑意义的是,DeepSeek-V4 从模型设计之初就深度适配国产算力,在华为昇腾芯片生态实测跑通,成为全球首个在国产算力底座上完成训练与推理的万亿参数级模型,打破对海外芯片与框架的长期依赖。
性能比肩顶级闭源模型,价格比Claude便宜21倍 官方实测数据显示,DeepSeek-V4-Pro性能比肩顶级闭源模型。
Agent(智能体)能力方面,相比前代模型,DeepSeek-V4-Pro的能力显著增强。
在 Agentic Coding 评测中,V4-Pro 已达到当前开源模型最佳水平,并在其他 Agent 相关评测中同样表现优异。
DeepSeek介绍,目前 DeepSeek-V4 已成为公司内部员工使用的 Agentic Coding 模型,据评测反馈使用体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式,但仍与Opus 4.6 思考模式存在一定差距。
DeepSeek给出的结论相对克制。
在知识与推理任务上,其性能已经超过主流开源模型,并接近Gemini等闭源系统,但仍存在约3到6个月差距。
在 agent和代码任务上,其表现接近甚至部分超过Claude Sonnet。
此外,在数学、STEM、竞赛型代码的测评中,DeepSeek-V4-Pro超越当前所有已公开评测的开源模型(包括月之暗面的K2.6 Thinking、智谱GLM-5.1 Thinking等),取得了比肩世界顶级闭源模型的优异成绩。
相较之下,DeepSeek-V4-Flash主打性价比,能够提供更加快捷、经济的 API 服务。
在 Agent 测评中,DeepSeek-V4-Flash 在简单任务上与 DeepSeek-V4-Pro 旗鼓相当,但在高难度任务上仍有差距。
据悉,V4-Pro 与 V4-Flash 最大上下文长度为 1M,均同时支持非思考模式与思考模式,其中思考模式支持 reasoning_effort 参数设置思考强度(high/max)。
对于复杂的 Agent 场景建议使用思考模式,并设置强度为 max。
使用价格如下: DeepSeek表示,“受限于高端算力,目前Pro的服务吞吐十分有限,预计下半年昇腾950超节点批量上市后,Pro的价格会大幅下调。
” 再看看国际友商价格对比,可见DeepSeek的实惠: 混合架构解决工程落地痛点,全面适配国产算力 大模型处理超长文本的最大痛点,从来不是 “能不能装下”,而是跑不动、记不住、算不起。
随着传统注意力机制呈平方级复杂度攀升,百万Token场景下显存与算力直接 “爆炸”,几乎无法工程落地。
DeepSeek-V4 的发布,标志着大模型正式走出 “参数竞赛”,进入效率优先下一代赛道。
从一口气审计全量代码库、一次性解析千页合同,到全程记住长时间会议、串联多轮复杂智能体任务,V4让AI 真正具备“完整理解、长期记忆、深度推理”的能力,同时把使用成本大幅下拉。
这一切得益于DeepSeek业内首创“CSA (压缩稀疏注意力) + HCA (重度压缩注意力)”的混合架构。
用一套“分级压缩 + 分级检索”思路,把效率拉到极致。
这一新方法显著减少了计算复杂度,提升了长上下文处理的效率。
具体来看,CSA像给长文本做重点精读。
先把每 4 个Token压缩成一个信息块,再用稀疏检索只挑最相关的内容,既保留中段细节,又大幅削减计算量,兼顾精准与效率。
HCA像给长文本做大纲速读,把海量信息浓缩成框架级块,专门负责全局逻辑。
官方数据显示:1M Token场景下,V4-Pro 仅需 V3.2 的 27% 推理算力、10% KV 缓存;
Flash 版更是低至 10% 算力、7% 缓存。
除了混合注意力,V4 还带来三项关键技术革新,构成完整效率革命: mHC 流形约束超连接:升级传统残差连接,把信号传播约束在稳定流形上,深层不衰减、训练不炸数值。
Muon 优化器:替代传统 AdamW,收敛更快、训练更稳,完美适配 MoE 大模型与低精度训练,解决大批次长上下文训练的抖动难题。
全链路工程优化:专家并行细粒度通信重叠、TileLang 内核开发、FP4 量化感知训练、异构 KV 缓存管理,从计算、通信、存储全方位降本提速,推理加速最高近2倍。
最受大家关心的,是V4这次是否成功全面适配国产算力? 报告指出,DeepSeek-V4在英伟达 GPU 与华为昇腾 NPU 两大硬件平台上,对细粒度 EP 优化方案完成了全面验证。
相较于性能优异的非融合基线方案,该方案在通用推理负载场景下可实现1.50~1.73 倍的加速比。
有业内观点指出,这代表已经完成华为昇腾平台的适配和实测落地。
但目前对外开源的只有英伟达GPU版本,昇腾适配代码未开源,属于闭源适配优化。
值得一提的是,寒武纪在软硬一体生态中,已经完成基于 vLLM 推理框架完成对 285B DeepSeek-V4-flash 和 1.6T DeepSeek-V4-pro 的适配,适配代码已开源到 GitHub 社区。
剩下的,就等DeepSeek-V4的实用表现了。
还有DeepSeek的首轮融资最终花落谁家,也还是个谜题。
“不诱于誉,不恐于诽,率道而行,端然正己。
” DeepSeek官方在文章最后表示,他们将始终秉持长期主义的原则理念,在尝试与思考中踏实前行,努力向实现 AGI 的目标不断靠近。
”
哺乳期的妈妈可不可以吃辣?
理论上讲,辣椒素属于大分子物质,难以通过乳汁影响宝宝,但部分宝宝会对含辣味的乳汁较为排斥,可能是不适应这种味道。妈妈可通过观察宝宝反应,适当控制吃辣椒的量。
请注意,在部分特殊情况下,哺乳期妈妈就不宜吃辣椒了。
比如处于便秘或腹泻期间,肠道功能本就较弱,吃过多辣椒会加重原有症状;
若身上有伤口,或处于坐月子期间,也不建议吃辛辣食物,以免影响伤口愈合。
另外,有家长反映吃辣椒后哺乳,宝宝会出现皮疹。
这类情况的原因较多,也可能是重油重盐等其他佐料添加过多所致,可尝试让妈妈在饮食上减油减盐。
(来源:首都医科大学附属首都儿童医学中心) 来源:北京12320在聆听
猜你喜欢
-
 沁阳税务:税法宣传进高校 春风送惠助成长 热点 2026-04-22
沁阳税务:税法宣传进高校 春风送惠助成长 热点 2026-04-22 -
 百度网盘上线AI宝宝相簿:自动识别人脸、智能归集成长照片 热点 2026-04-19
百度网盘上线AI宝宝相簿:自动识别人脸、智能归集成长照片 热点 2026-04-19 -
 刷爆地下城上线Steam:快节奏数值成长地牢RPG,支持中文免费试玩 热点 2026-04-19
刷爆地下城上线Steam:快节奏数值成长地牢RPG,支持中文免费试玩 热点 2026-04-19 -
 金融知识进校园 守护成长“钱袋子” 热点 2026-04-17
金融知识进校园 守护成长“钱袋子” 热点 2026-04-17 -
 童趣研学启新程,小北路小学开启“小蚂蚁”微研学 热点 2026-03-23
童趣研学启新程,小北路小学开启“小蚂蚁”微研学 热点 2026-03-23 -
 幼儿园老师带班“三十六计”,看过的幼师都在用! 热点 2026-03-19
幼儿园老师带班“三十六计”,看过的幼师都在用! 热点 2026-03-19 -
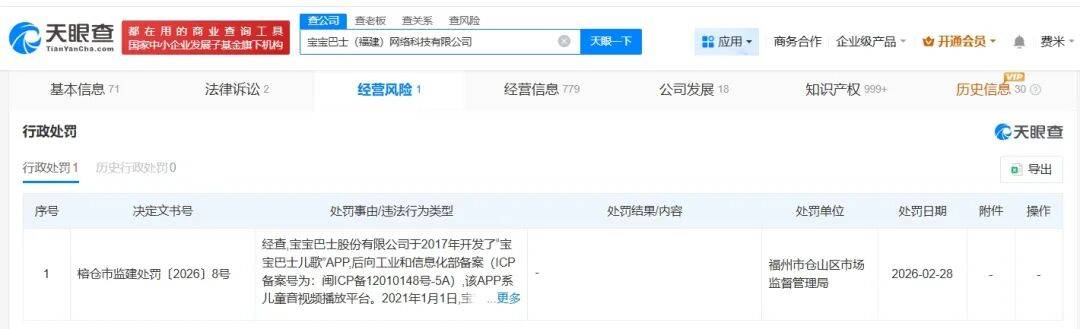 展示“三女共侍一夫,每月50万生活费”,获利3.68元,宝宝巴士被罚30万!称有8亿用户 热点 2026-03-18
展示“三女共侍一夫,每月50万生活费”,获利3.68元,宝宝巴士被罚30万!称有8亿用户 热点 2026-03-18 -
 育儿知识送上门!这里带你解锁科学育儿新方式 热点 2026-03-16
育儿知识送上门!这里带你解锁科学育儿新方式 热点 2026-03-16 -
6个月的宝宝睡觉时猛摇头、抓耳朵应该解决办法? 怀孕 2026-05-03
-
家有新宝宝一月哭二月闹三月不睡觉婴儿发育口诀你记住了吗? 怀孕 2026-05-03
-
5月是孩子长个黄金期爸妈一定要做好这四点 怀孕 2026-05-03
-
五个月宝宝的发育情况、具备了哪些能力来看看你家娃达标了吗? 怀孕 2026-05-03
登录后畅享更多功能




