两个月的婴儿可以坐吗?
月子
2026-05-09
菜科探索
+

简介:两个月的宝宝虽然已经比起出生的时候要适应没有妈妈羊水的生活,有的甚至能够稳当地抬着头、或者是对大人露出危险,但是他们的身体发育还是很不成熟的。
有的妈妈会觉得孩子
【菜科解读】
两个月的宝宝虽然已经比起出生的时候要适应没有妈妈羊水的生活,有的甚至能够稳当地抬着头、或者是对大人露出危险,但是他们的身体发育还是很不成熟的。
有的妈妈会觉得孩子应该开始学习坐着,但是也害怕对宝宝身体不好,所以很多人都会问到,两个月的婴儿可以坐吗?

其实两个月的小宝宝还只能平抱,要不然对小宝宝的脊椎不好,等3个月的时候才能开始慢慢竖着抱,也可以慢慢让宝宝靠着东西坐,不过这个都不能坐太久的,宝宝还太小了等到再长大些再慢慢开始学坐。
各位妈妈可以在护理时应该注意以下几点。
1、使用爽身粉
家长们都喜欢在宝宝洗澡后,帮宝宝擦上爽身粉,让宝宝的皮肤更干爽舒适,特别是到了夏天,为了防止宝宝长痱子,很多家长更喜欢选用爽身粉了。
专家们指出,爽身粉如果长期使用不当,尤其是对婴幼儿,会损害健康。
2、宝宝衣服

婴儿适合穿柔软、吸湿、透气性好的,用纯棉制品制作的衣服。
衣服式样应简单、宽松,不妨碍小儿四肢及躯体活动。
纯棉制品很重要,许多婴儿夜哭皆是由于穿化纤制作的衣服,引起皮肤过敏及不适引起的。
3、剪指甲
防止新生儿抓破皮肤最根本、有效的方法是经常给新生儿剪指甲。
为避免新生儿把脸抓伤,家长可以趁孩子熟睡时小心仔细地修剪。
新生儿的指甲要比任何人的指甲都要柔软,所以如果要给孩子剪,一定要很小心。
4、保证每天约17-20个小时的睡眠
良好的睡眠有利于机体的新陈代谢,促进宝宝的生长发育。
有的宝宝睡眠时间会长一些,有的宝宝会短一些,只要宝宝精神状态好,食欲好,无异常哭闹,生长发育正常就说明睡眠时间足够,睡眠质量好。

5、多多关爱宝宝
多拥抱、爱抚宝宝,抚摩宝宝全身的皮肤,与宝宝说话;经常用微笑、歌声、鲜艳的有声玩具逗引宝宝。
各位所疑惑的“两个月的婴儿可以坐吗?”这个问题已经有了答案。
婴儿虽然不会说话,但是我们也要多多跟他互动,密切留意他们的表现,跟他们说说话,逗他们玩,对于宝宝的学习跟成长是非常有帮助的。
平时也应该多关注育婴方面的信息,有利于照顾孩子。
英伟达力荐,小团队两个月开源一款「光速级」智能体推理引擎
机器之心编辑部 智能体时代的核心是算力。尤其是在 Coding Agent 爆发之后,算力问题变得前所未有地尖锐。
Claude Code、Codex、Cursor 等产品正在把 AI 从「问答工具」变成「持续运行的软件协作者」,单次会话轻松突破 50K tokens,系统负载转向了更极端、更复杂的智能体负载。
最近有关算力的大新闻层出不穷。
今天的最新消息:马斯克的 SpaceX 与 Anthropic 宣布达成了重磅协议,超过 22 万块英伟达 GPU 将为 Anthropic 所用。
而 Anthropic 对与 SpaceX 合作开发未来的太空算力体系「表示有兴趣」。
在如此庞大的算力需求下,除了开源还有节流。
也是今天的最新消息:OpenAI 发布了多路径可靠连接 (MRC),可帮助大型 AI 训练集群更快、更可靠地运行,并减少 GPU 时间的浪费。
我们知道,即便只是单 GPU 吞吐率上的微小提升,一旦应用到生产级集群中,也能够在服务持续增长需求的同时,节约相当可观的算力。
来自 LightSeek Foundation 的一个小团队,在两个月时间内打造了一个全新的,号称「光速」的大模型推理引擎 TokenSpeed。
这一引擎拥有 TensorRT LLM 级别的性能,vLLM 级别的易用性。
并且拥有 NVIDIA Blackwell 上最快的 MLA 注意力内核。
一经发布,TokenSpeed 就受到了英伟达发推文力荐。
目前,该引擎已经开源。
让我们参阅其技术博客,来深入了解「光速」引擎的技术细节。
博客标题:TokenSpeed: A Speed-of-Light LLM Inference Engine for Agentic Workloads 博客链接:https://lightseek.org/blog/lightseek-tokenspeed.html Github 链接:https://github.com/lightseekorg/tokenspeed TokenSpeed 技术简介 TokenSpeed 从第一性原理出发,专门为智能体推理场景设计。
它为智能体负载提供接近「光速级」的推理能力,核心包括:基于编译器的并行建模机制、高性能调度器、安全的 KV 资源复用约束、支持异构加速器的可插拔分层 kernel 系统,以及用于低开销 CPU 侧请求入口的 SMG 集成。
建模层采用本地 SPMD(Single Program, Multiple Data,单程序多数据)设计,在性能与易用性之间取得平衡。
TokenSpeed 允许开发者在模块边界指定 I/O placement 注解。
随后,一个轻量级静态编译器会在模型构建过程中自动生成所需的 collective operation,从而无需手动实现通信逻辑。
TokenSpeed 调度器将控制平面(control plane)与执行平面(execution plane)解耦。
控制平面使用 C++ 实现,并被构建为一个有限状态机(FSM),结合类型系统,在编译期而非运行期强制执行安全资源管理,包括 KV cache 状态转移与使用。
请求生命周期、KV cache 资源以及重叠执行时序,都通过显式 FSM 状态迁移与所有权语义进行表示,因此系统正确性并非依赖约定,而是由一个可验证的控制系统来保证。
执行平面则使用 Python 实现,以保持开发效率,使研究人员与工程师能够更快进行功能迭代,并降低整体认知负载。
TokenSpeed 的 kernel 层将 kernel 从核心引擎中解耦,并将其视为一级模块化子系统。
它提供了可移植的公共 API、集中的注册与选择机制、组织良好的实现结构、面向异构加速器的可扩展插件机制、经过整理的依赖体系,以及统一的快速迭代基础设施。
与此同时,团队还针对 NVIDIA Blackwell 架构进行了大量性能优化。
例如,他们构建了当前智能体负载场景下速度最快的 MLA(Multi-head Latent Attention,多头潜在注意力)kernel 之一。
在 decode kernel 中,由于部分场景下「num_heads」较小,团队通过对「q_seqlen」与「num_heads」进行分组,以更充分利用 Tensor Core 的计算能力。
而 binary prefill kernel 则包含了经过精细调优的 softmax 实现。
目前,TokenSpeed MLA 已被 vLLM 采用。
TokenSpeed 性能预览 Coding Agents(编码智能体)带来了异常严苛的推理工作负载,上下文通常会超过 50K tokens,对话也经常跨越数十轮。
大多数公开基准测试并不能充分捕捉这种行为。
研发团队与 EvalScope 团队一起,基于 SWE-smith 轨迹对 TokenSpeed 进行评估,这些轨迹密切反映了生产环境中 Coding Agents 的流量情况。
由于生成速度对 Agent 的用户体验至关重要,因此,团队的目标是在维持单用户 TPS(每秒 token 数)下限的同时,最大化单 GPU 的 TPM(每分钟 token 数)—— 通常是 70 TPS,有时是 200 TPS 或更高。
此外,研发团队针对 TensorRT-LLM(目前 NVIDIA Blackwell 平台上的最高水平)对这一设计进行了基准测试,并在认为针对 Agentic workloads 存在更好权衡的地方,采取了与之不同的设计方案。
下图展示了在不同部署配置下(无 PD 解耦),TokenSpeed 与 TensorRT-LLM 的 Kimi K2.5 性能帕累托曲线(Pareto curves)。
每条曲线都以 TPS/User(横轴)作为延迟指标,以 TPM/GPU(纵轴)作为吞吐指标,并通过扫描并发数绘制而成。
对于 Coding Agents(高于 70 TPS/User),最佳配置是 Attention TP4 + MoE TP4。
在这一配置下,TokenSpeed 在整个帕累托前沿上均优于 TensorRT-LLM:在最低延迟场景下(batch size 1)大约快 9%,在 100 TPS/User 附近吞吐量大约高 11%。
团队表示,他们的核心优化之一是 TokenSpeed MLA。
下图对比了 TokenSpeed MLA 与 TensorRT-LLM 的 MLA,后者是目前 NVIDIA Blackwell 上的 SoTA。
可以看出来,优化后的二进制版本预填充内核(prefill kernel),使用 NVIDIA 内部旋钮来微调 softmax 实现,在 Coding Agents 的五种典型预填充工作负载(带长前缀 KV cache 的 prefill)中,都超过了 TensorRT-LLM 的 MLA。
解码内核则将查询序列轴折叠进头轴,以更好地填充 BMM1 的 M tile,从而提升 Tensor Core 利用率。
结合其他优化,在带有 speculative decoding 的典型解码工作负载中(batch size 为 4、8、16,且带长前缀 KV cache),这使得相对于 TensorRT-LLM 来说,延迟几乎降低了一半。
最后,研发团队也表示,该项目于 2026 年 3 月中旬启动开发,虽然目前展示了惊人的性能,但仍有大量底层代码(如 PD 分离、KV 存储等)正在合并和完善中,接下来将继续推进。
从上述性能表现来看,不难看出,TokenSpeed 的出现旨在通过更现代化的架构设计,打破传统推理框架在易用性与极致性能之间的平衡点,为大规模 Agent 部署提供了一个高性能、开源的底座。
而英伟达的力荐,也说明推理引擎正在成为 Agent 时代基础设施竞争的一个新焦点。
更多信息,请参阅原博客! 参考链接: https://x.com/lightseekorg/status/2052048105412141376 https://x.com/NVIDIAAI/status/2052061195381911806
女子跟房东结婚引热议,新郎真的叫“房东”
5月5日,山西太原的一场婚礼引热议,印着“房东先生&王女士”的婚礼拱门被路人拍下引发网友热烈讨论。“你对象真叫这个名字?我以为你们在玩梗!”半个月前,山西太原王女士给老同学发婚礼请柬时,几乎每个人都发出了这样的疑问。
记者联系上新娘王女士,此时她老公“房东”正在开车,小两口刚结束婚假回到工作岗位。
王女士说,自己和老公都是95后,去年8月因为工作交集认识。
“有些网友不太清楚情况,我还特意去帖子下留言,说我老公名字真的叫‘房东’。
”谈及两人相识的原因,王女士介绍,“因为工作关系,有一次我收集合作单位的报名表,然后在一堆表格里第一次见到‘房东’这个名字就记住了。
”后来,两人渐渐互生好感。
说起“房东”这个名字的趣事,王女士说,最经典的一次是前段时间她和老公一起看房子,她在小区里连着喊了几声“房东”,带他们看房子的小哥连忙上前说:“房东今天没来,有啥事跟我说就行。
”直到王女士指着身边的老公解释,对方才恍然大悟。
对于自己的名字,房东告诉记者,自己本职工作是律师,因为名字的关系,每次开庭都要被法官反复确认:“房东来了吗?你真叫房东?”这也成了法庭上一个有趣的小插曲。
为什么会取“房东”这个名字?王女士还特意问了长辈。
王女士说,老公房东有个哥哥,取名的时候很费心思,后来有第二个儿子,他爸爸开玩笑说“就不翻字典了,随便取取好记就行。
‘东’是东方,是希望升起的地方,有期待的意思。
再搭配上房姓,简单好记”。
这场因名字走红的婚礼,还让网友们发现了一个有趣巧合:新娘王女士叫王嘉欣,名字“嘉欣”发音和“加薪”很像,“房东”配“加薪”,被网友祝福“这日子注定越过越富”。
来源:都市快报记者 董吕平 编辑:戚浩然 校对:蔡佳
猜你喜欢
-
 婴儿期创伤~精神黑洞 热点 2026-05-07
婴儿期创伤~精神黑洞 热点 2026-05-07 -

-
 汗臭与狐臭:气味、成因大不同,一文揭秘背后的科学原理 热点 2026-05-07
汗臭与狐臭:气味、成因大不同,一文揭秘背后的科学原理 热点 2026-05-07 -
上海一民警卷裤腿跳进淤泥捞手机:是我们应该做的,不止是我,周围人都很帮忙 热点 2026-05-07
-
 美军炸毁伊朗油轮! 热点 2026-05-07
美军炸毁伊朗油轮! 热点 2026-05-07 -
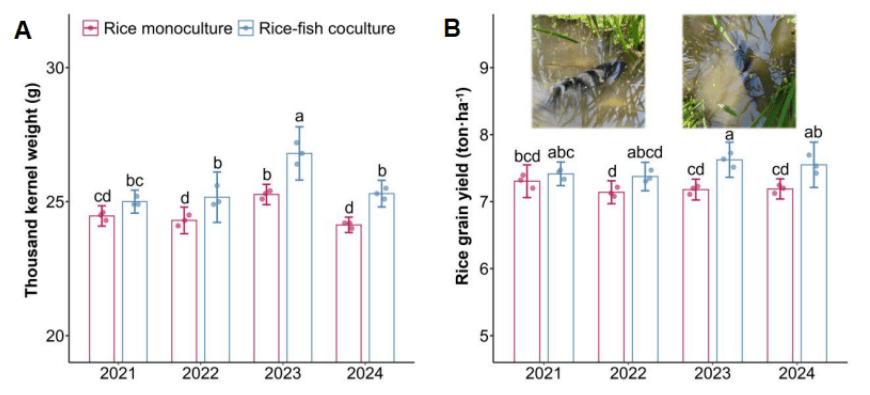 华理学者联手多国科学家,揭开“稻鱼共生”千年农法的科学奥秘 热点 2026-05-07
华理学者联手多国科学家,揭开“稻鱼共生”千年农法的科学奥秘 热点 2026-05-07 -
 喜报丨五月事业Buff叠满的星座TOP5! 风水 2026-05-06
喜报丨五月事业Buff叠满的星座TOP5! 风水 2026-05-06 -
-
两岁宝贝说话晚怎么办? 月子 2026-05-09
-
 两个月宝贝吐奶瓣怎么办? 月子 2026-05-08
两个月宝贝吐奶瓣怎么办? 月子 2026-05-08 -
 坐月子产妇应该怎样刷牙坐月子刷牙牙齿会松动吗? 月子 2026-05-08
坐月子产妇应该怎样刷牙坐月子刷牙牙齿会松动吗? 月子 2026-05-08 -
想要新生儿安全过冬做好“三个注意”?想要宝宝安全过冬做好“三个注意” 月子 2026-05-08
登录后畅享更多功能



