天启堆料王发威这款RTX3060太暴力天启堆料王发威
释疑解惑
2026-07-14
菜科探索
+

简介:天启堆料王发威索泰GeForceRTX3060-12GD6天启OC评测规格参数基础频率:1320MHz加速频率:1807MHz显存频率:15000MHz显存容量:
【菜科解读】

索泰 GeForce RTX 3060-12GD6 天启 OC评测
规格参数
基础频率:1320 MHz
加速频率:1807 MHz
显存频率:15000 MHz
显存容量:12 GB/GDDR6
显存位宽:192 bit
供电辅助:双8Pin
整板功耗:170W
推荐电源:550W
散热系统:5热管天启3风扇散热器
输出接口:DP 1.4a×3 HDMI 2.1
参考价格:3599 元
广大玩家盼望的RTX 3060终于正式发布,它不但带来了远超上代"60"甜品显卡的性能,还带来了高达12 GB的显存,相比上代"60"显卡足足提升了一倍,性价比非常突出。
索泰作为NVIDIA的核心合作厂商,在第一时间推出了旗下的RTX 3060显卡线,而索泰 GeForce RTX 3060-12GD6 天启 OC则是其中以豪华用料与高规格散热著称的强力代表。
RTX 3060中的堆料王,天启RTX 3060相当"壕"
天启系列作为索泰旗下次旗舰显卡,由之前的至尊PLUS系列全面升级而来,并在此基础上注入二次元灵魂,打造了专门的二次元形象"天启姬"。
从天启姬的形象设计我们就可以了解天启系列RTX 30显卡的一些特点:天启姬身穿银黑色的钧天装甲,坚固却不失灵巧的装甲大大提升了天选姬在战斗时的防护力;
天启姬身后的翅膀名为天启之翼,由飞翼和螺旋桨组合而成,对气流掌控自如,有效增强了机动性;
手持长枪,名曰启世之环,枪中心的圆环流光溢彩,光彩夺目,华丽的外表下也有着不俗的实力。
接下来我们详细了解一下天启RTX 3060显卡的卖点。
★钧天装甲

索泰 GeForce RTX 3060-12GD6 天启 OC的散热风罩采用装甲式造型设计,在经典的黑色基底上加装银色盔甲,棱角分明且神秘感十足。
★天启之翼

显卡的全金属装甲背板的"天使之翼"图案上预留了两个风扇位,玩家额外购买专用风扇安装上去之后,就可以组成5风扇散热系统(背后的风扇直吹供电区域和GPU区域),同时也做到了ARGB灯效的全面覆盖,通电之后视觉效果非常震撼。
当然,5风扇设计也实实在在地增强了显卡的散热能力。
★8 2相数字供电

索泰 GeForce RTX 3060-12GD6 天启 OC配备了8 2相数字供电,并提供了双8 Pin辅助供电,供电能力远远超过了RTX 3060标配170W的整板功耗设定,因此也就预留出了足够的超频发挥空间,同时满载工作的时候供电元件温度更低、寿命更持久。
★冰镜导热模组

这款显卡配备了索泰独家冰境导热模组,针对GPU导热进行了优化,提供大面积一体铜铸散热模块,可以做到全面覆盖GPU核心;
散热片底部采用镜面抛光工艺,让底座和GPU可以充分接触,而底座与热管、鳍片之间也通过回流焊工艺紧密结合,让整个导热模组浑然一体,能够更快速、高效地导出GPU产生的热量,降低GPU的工作温度。
此外,显卡散热器中还提供了5条冰脉复合热管,通过增加热管壁厚度、新增热管内壁脉络状导液沟槽的方式,加大了冷凝液与热管内壁的接触面积,从而加快冷凝液导热循环,有效降低热阻,提升热管导热效率。
★RGB信仰灯效

显卡正面的光环与顶部的LOGO都提供了RGB灯效,通过索泰自家的FireStorm工具就可以实现灯效控制,打造出极具个性化的信仰灯效。
从目前上市的RTX 3060显卡来看,索泰 GeForce RTX 3060-12GD6 天启 OC 的超厚散热片3风扇5热管散热设计确实算得上是非常豪华的配置了,因此我们也非常期待它的实战表现。
实战测试:天启能量爆发,暴力甜品非它莫属
测试平台
显卡:索泰 GeForce RTX 3060-12GD6 天启 OC
主板:技嘉Z590 AORUS MASTER
处理器:Intel酷睿i9 10900K
内存:威刚XPG D50 DDR4 3600 8GB×2
硬盘:西部数据 SN850 1TB
电源:航嘉MVP K650B
操作系统:Windows 10 64bit 20H2专业版
驱动程序:NVIDIA Game Ready Driver 461.64
基准测试
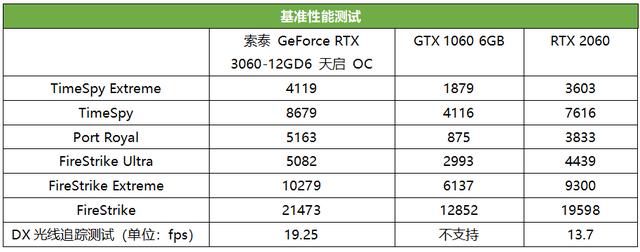
基准测试部分,天启RTX 3060相对于RTX 2060的DX11和DX12性能都最多提升了约15%,DXR光追性能则提升最多42%。
和GTX 1060相比的话,天启RTX 3060的优势甚至最多达到了117%,而由于GTX 1060无法支持硬件级光线追踪加速,因此在Port Royal中的帧率非常低,DX光线追踪测试项更是无法运行,看来要享受新一代光追游戏,升级到RTX 3060是很有必要的。
光追游戏测试
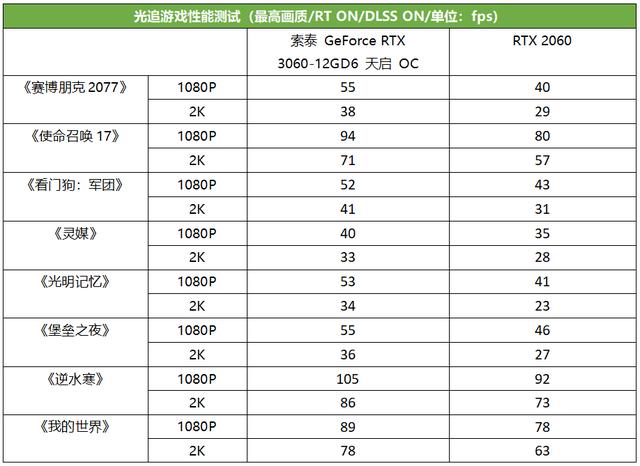
从光追游戏测试成绩来看,在玩《赛博朋克2077》这类光追特效特别齐全的游戏时,天启RTX 3060相对RTX 2060的优势特别明显,帧率增幅最高可达40%,《光明记忆》测试中,RTX 3060的优势甚至最高可达46%,其余的光追游戏中,天启RTX 3060的优势也最多达到了32%,看来RTX 3060更大的显存容量和更高显存频率在这里起了明显作用。
光栅化游戏测试
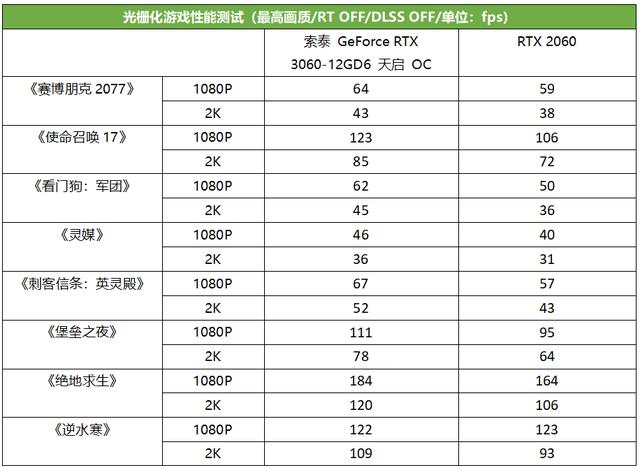
在关闭光追的游戏大作中,天启RTX 3060相对于RTX 2060的帧率优势最多可达27%,大部分游戏中RTX 3060的优势都在20%以上,只有《赛博朋克2077》这样比较吃处理器的游戏中优势稍小。
由此可见,开启光追和DLSS更能体现出RTX 3060的架构优势。
专业性能测试
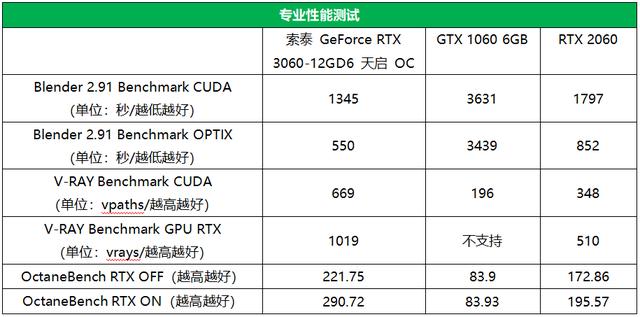
天启RTX 3060依靠第二代RT Core和第三代Tensor Core,也可以在各种渲染器中更好地支持带有光追特效的渲染。
从测试成绩可以看到,天启RTX 3060相对RTX 2060的渲染性能优势最多达到了91%,可以说在生产力方面,RTX 3060明显高出RTX 2060一到两个档次。
值得注意的是,由于GTX 1060不具备光追单元,因此在光追渲染时还是用的CUDA单元进行计算(或者干脆就不支持),因此成绩与CUDA模式下几乎相同,但这样一来,光追渲染的性能就只有RTX 3060的1/6。
因此,如果你的设计师PC还在使用GTX 1060,赶紧升级到RTX 3060或更高型号就可以获得数倍的渲染效率提升。
温度与功耗表现
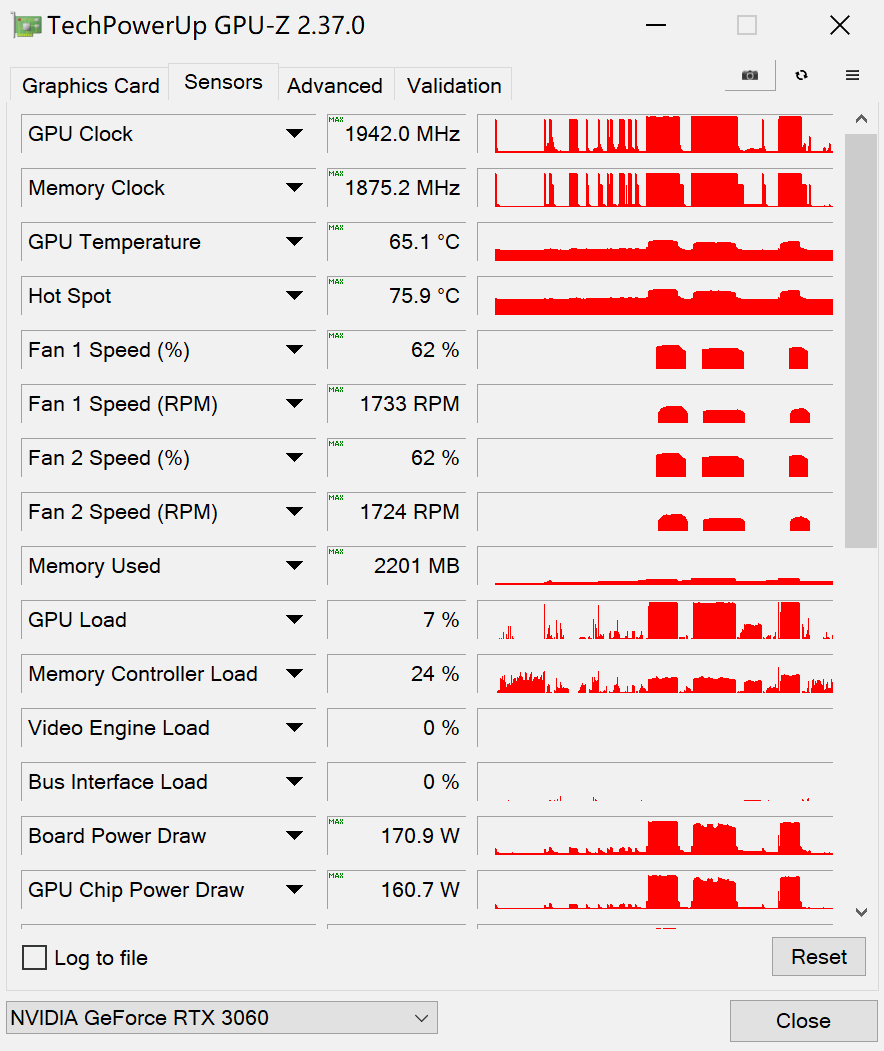
默认设置考机,GPU温度最高65.1℃
索泰 GeForce RTX 3060-12GD6 天启 OC的3风扇5热管散热器在RTX 3060显卡中算非常高的散热规格了,而且它的厚度也达到了60mm,散热效果自然不俗。
从考机实测来看,默认设置下,GPU最高温度仅为65.1℃,风扇转速仅为62%,十分静音。
此外,整板功耗也保持在标准的170W水平上。
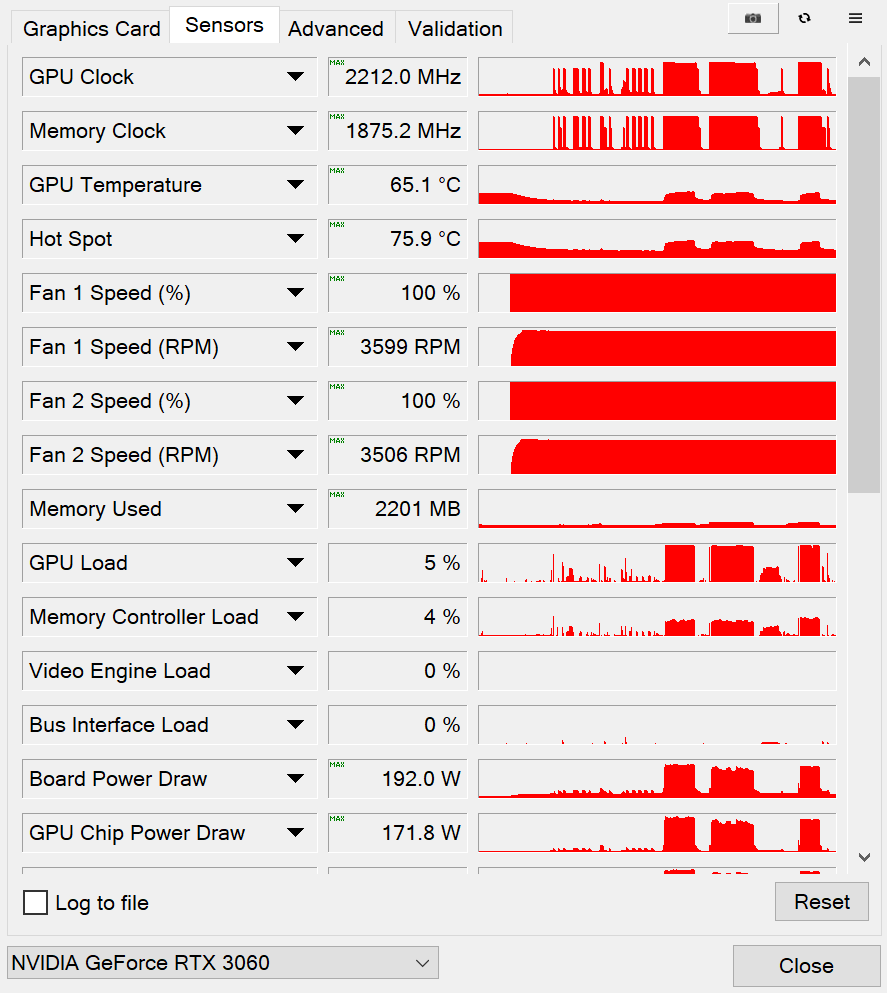
将GPU频率手动提升220MHz,考机温度也没有超过65.1℃,性能提升接近10%
既然索泰 GeForce RTX 3060-12GD6 天启 OC的散热与供电都非常出色,我们当然要试试超频。
我们将显卡的功耗墙提升到了117%,风扇转速开满,然后经过反复尝试,最终将GPU频率手动提升了220 MHz,此时在3DMark测试中,GPU的最高频率达到了2212 MHz之高,这个水平也是相当不错了。
从图上也可以看到,即便是超频之后考机,GPU温度也没有超过65.1℃,可见天启RTX 3060的散热器性能确实非常出色。
总结:RTX 3060高性价比堆料王,天启之力值得拥有
和市售一众RTX 3060相比,索泰 GeForce RTX 3060-12GD6 天启 OC无论是双8 Pin搭配8 2相供电还是3风扇5热管散热器都堪称豪华配置,而且实测性能远远超过上代"60"甜品光追显卡,良好的散热更能保证显卡长时间稳定释放性能,再加上3599元的犀利价格,确实值得玩家优先考虑。
当然,对于主流设计师用户来讲,索泰 GeForce RTX 3060-12GD6 天启 OC配备的12 GB超大显存也可以有效提升工作效率,选择它组建NVIDIA STUDIO系统也是一个高性价比的方案。
猜你喜欢



























登录后畅享更多功能